| Dave Higgins Consulting Strategic Technology Consulting and Enterprise Architecture |
Home | What's New | What's Old | Articles | Associates | Interesting Links | Cool Stuff |
Section 4: Logical Design
Introduction
In this section we will explore the three stages of logical
design. It is assumed for the purposes of this tutorial that the
Requirements Definition phase of the DSSD lifecycle has been
largely completed, and that the outputs and inputs to a program
have been identified.
The DSPD program design method which follows can be used with any
methodology, as long as the outputs and inputs to a program have
been previously defined.
Output Prototypes
You will recall that the most fundamental principle of the
Warnier/Orr methodology is that development must be output
oriented. In program design, this means that understanding the
output is crucial to the correct development of the program.
Therefore the first stage of DSPD is the development of a sample
of the output. This is often known as a "prototype" or
a "model."
Different types of outputs may require different levels of
prototyping, however one aspect all prototypes share: they show
real data--real names, real numbers, real calculations. This is
an important concept. Too often in the past the client receiving
an output never saw real data on the output until AFTER the
program was already written. And it is one of the oldest cliche_s
in the industry that clients always make changes to outputs
whenever they see them for the first time. It is highly
preferable to know about those "changes" before the
program is developed the first time. Also, the ability to develop
the sample of the output "by hand" demonstrates that
the program developer knows what the program will have to do.
There are three levels of output prototypes.
1) Static Prototypes: A "picture" of an output. This is
best suited to outputs which do not "move" such as
reports or inquiry screens.
2) Dynamic Prototypes: A "movie" of an output. This is
best suited to outputs which change over time, such as a series
of screens in an on-line conversation. While simulating the
operation of an output, a dynamic prototype doesn't actually
"work." For that, we need one final level of prototype.
3) Working Model: A scaled down version of the intended system.
In other words, it allows some user input and will reflect that
input in the outputs that are produced. Great caution should be
used in developing working models, however: there is a great
temptation to try to "refine" them into being the
finished system (and then you are right back to traditional
iterative development--which we know doesn't work very well). A
working model should be developed only in the absence of stable
requirements: once the requirements become stable the model
should be abandoned and the development effort should proceed
normally.
Once the output prototype has been completed and the client who
will receive the output has seen and approved the prototype, we
will begin to formally gather some information about the output
and its program design.
(In practice, this is not necessarily a linear process...as part
of the development of the prototype the information gathered in
the following stages may be collected informally and documented
in the manner indicated. This information may in fact help the
developer to create the finished prototype. However, the
information gathered is not finalized until after the prototype
is approved. So there.)
Output Requirements
The "Output Requirements" requires the program
developer to ask the following questions (and document them in an
appropriate manner and location, generally on an Output
Requirements Form).
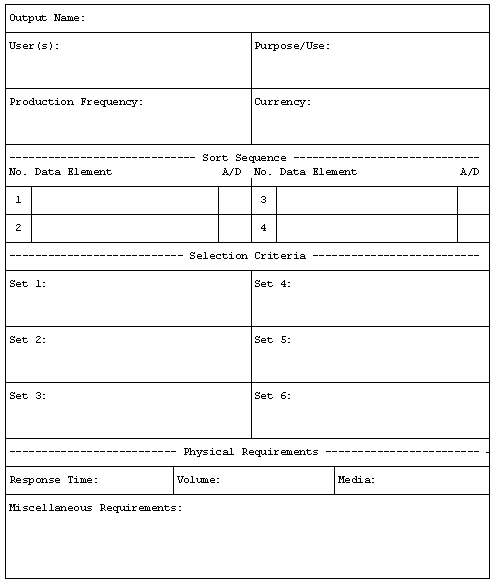
1) Output Name: The name of the output.
2) Client Name: The name of the person inside the organization
who receives the output and must be satisfied with it's content.
The person (or other system) which will "use" the
output.
3) Purpose/Use: A brief description of the use of the data on the
output.
4) Production Frequency: A statement as to how often the output
will be produced. Generally expressed as some kind of event (such
as "Month End").
5) Currency: A statement as to how current is the data present on
the output. Also generally expressed as some kind of event.
Also some physical output characteristics are generally captured,
such as...
6) Volume: How large (voluminous) is the output anticipated to
be?
7) Response Time: How quickly must the output be presented to the
client after it is produced?
8) Media: What media is the output produced on?
Also captured for each output...
9) Sorting Sequence: For each data element used to sequence the
data on the output, the name of the element is documented, as
well as it's position in the sort (i.e., first, second, third,
etc.) and it's order (ascending or descending).
10) Selection Criteria: For each grouping of data on the output
(for each logical set of data present on the output), the
selection criteria for that set is documented, as are any data
element(s) which must be present in the data base to achieve that
selection. In other words, if data is to be grouped on the output
by Customer the selection criteria answers the question: "of
all customers ever known to the organization, which customers
belong on this output?" If, for instance, only
"preferred customers" are to be presented on the
output, one would document that fact, along with the fact that a
"Preferred Customer Indicator" must also be present in
some form in the data.
Also captured if necessary...
11) Miscellaneous Requirements: If any other information is
learned about the output which does not fit into any of the above
classifications, it is noted. These miscellaneous requirements
may or may not impact the program design or the data base design,
but they are captured here so that they may be reviewed later as
part of quality assurance (to determine if they do indeed have an
impact on the systems design, or just seemed to be an interesting
fact at the time).
Output Requirements Form:
Sample Output Requirements Form:

Output Definition
The "Output Definition Form" asks the program developer
to gather some detailed information about the data on the output,
and about the nature and groupings of that data. It is used to
build the logical design (the LOS, LDS, and LOM discussed in the
following sections).
To begin with, the output prototype is inspected and all
so-called "physical data" is eliminated from immediate
consideration. For each piece of data we ask the question:
"If the input and/or output devices change, would that data
still be present on the output?" If the answer is yes,
chances are that the data is "logical" output data, and
will be appropriate to analyze for the logical design. If the
answer is no (the presence of the data depends on the input
and/or output device) then the analysis of the data will be
postponed until physical design.
In other words, we would like to analyze only the
"core" of data present on the output regardless of the
input and output devices. This data conveys the real
"meaning" of the output (if that data is not present,
the person on system which receives the output could not put it
to the use intended).
Once this logical core group of elements has been determined, the
following information is captured for each logical data element
on the output:
1) Data Element Name: The name of the fact or data item. Usually
the name has two parts: <set name>+<attribute>. The
set name is a qualifier which says which real-world actor,
commodity, message, relationship, or event the element is a fact
about. The attribute part names the kind of data: whether it is a
"name," an "amount," a "value,"
etc. Good names therefore would be names such as "Customer
Name," "Vendor Number," and "Invoice
Total." Poor element names lack either or both parts:
"Warehouse," "Description," and "Grand
Total" are all poor data element names, for example.
2) Appearance Frequency: How often the data element appears on
the output. Expressed in the form "Once per <some logical
set>," as in "1/Company,"
"1/Division," or "1/Invoice." The data
element must always appear once and only once for each member of
the logical set named, or the frequency is incorrect (i.e., the
frequency cannot be "0 or 1 per Customer" but should
instead be "1/Preferred Customer"; similarly the
frequency cannot be "1 to many times per Customer" but
should instead be "1/Invoice").
3) Local Element Type: Using just this output as a guide (and not
knowledge of any other outputs or knowledge of the actual input),
determine whether the element is:
3a) A Label: The data is the name of a "column" or
"row" on the output. In general, labels are
descriptions of the data on the output which do not change from
one instance of the output to another.
3b) Computed: In examining the output, the data is clearly
computed from data present on the output (or strongly inferred by
the data on the output).
3c) Required as Input: The contents of the data must be supplied
in order for the output to be produced (note that this does NOT
imply that the data is on the actual input file...it says that
the logical mapping needs the data to produce the output).
Label elements are flagged with "L", computed elements
with "C", and required elements with "*" on
the Output Definition Form.
For Computed Data Elements, the following is also captured:
Calculation Rule(s): Each calculation rule which is used to
manipulate the contents of the data element is documented, along
with the frequency that the rule must be applied. For example,
"Company Total" might have two calculation rules: 1)
Move Zero to Company Total and 2) Add Customer Total to Company
Total. Rule 1 has a frequency of once per Company; rule 2 has a
frequency of once per Customer. The calculation rules and the
calculation frequencies are documented on the Output Definition
Form.
For Required as Input elements, we also capture:
Input (or Change) Frequency: How often does the contents of the
data element change (which is the same as asking how often does
the element have to be supplied as input to be able to produce
the output).
Note that this input frequency is generally the same as the
output frequency gathered earlier, except for sorting data which
is output more frequently than its contents change (for example,
when listing Invoice Date for many invoices within a customer,
the output frequency for Invoice Date is once per invoice; its
input frequency is once per Invoice Day, assuming invoices are
sorted by date--in other words, if 1000 invoices are printed for
one customer, the Invoice Date will appear 1000 times on the
output, but will only change 5 times if only five day's worth of
invoices are represented on the output).
Output Definition Form
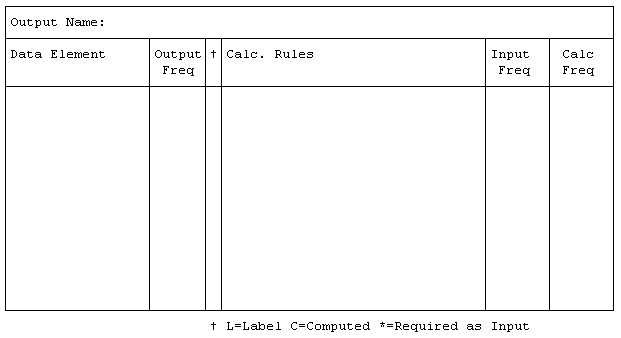
Sample Output Definition Form

Home | What's New | What's Old | Articles | Associates | Interesting Links | Cool Stuff |
This web site and all
material contained herein is Copyright ©2002-2009 Dave
Higgins. All Rights Reserved. For additional information,
please contact me at: |