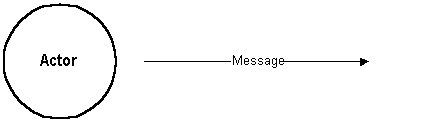
| Dave Higgins Consulting Strategic Technology Consulting and Enterprise Architecture |
Home | What's New | What's Old | Articles | Associates | Interesting Links | Cool Stuff |
Logical Data Base Design Concepts
©Copyright 1990-2002 Dave Higgins. All Rights Reserved.
Introduction
Several years ago my colleagues and I authored a systems
development methodology that came to be known as the Warnier/Orr
approach (named for Kenneth T. Orr and the late Jean-Dominique
Warnier). Its approach to
data base design is an extension of both relational data base
theory and Warnier's original L.C.S. (Logical Construction of
Systems) method. The Warnier/Orr logical data base design
approach represents a departure from these traditional data base
design techniques, however. While similar in many respects to
relational data base methods, it eschews conventional data
normalization in favor of a more direct approach to logical data
design. The result is a highly stable yet flexible logical data
base design that can be implemented in any physical environment.
Actors and Messages
In order to place the Warnier/Orr data base design method in
proper context, it is important to define a bit of terminology
associated with our Requirements Definition method.
Fundamentally, information systems (and their underlying data
bases) concern human communication: getting data from the people
(or institutions or systems) that have the data to the people (or
institutions or systems) that need the data. Therefore it is
important to understand the requirements of the communication
environment associated with a given system. In order to model the
communication environment (often known as the systems' context)
we employ a diagram we now call an actor/message diagram. [We
originally called them entity diagrams, but then later changed
the name to avoid confusion when entity-relationship diagrams
became popular.] Actor/message diagrams have only two
diagrammatic components: a named bubble representing an actor in
the system context, and a named arrow representing some type of
message or communication.
Figure 1: Actors and Messages
Actors are those people, institutions or information systems that are capable of sending or receiving information. They most often refer to the role that an actor plays in the context of the system. Messages are the information or transactions transmitted between the actors. A simple example of the way in which such a diagram would be used to describe the context of an accounts receivable system is shown in the following figure. In the example, the Customer and the Company are the actors, while the Order, Shipment, Bill, and Payment are the messages.
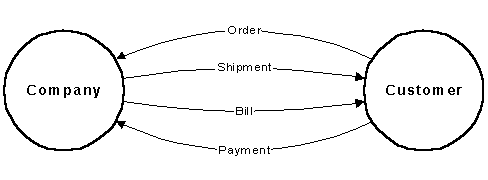
Figure 2: Example A/M Diagram
While not explicitly depicted on an actor/message diagram, three other important system features are implied. First, the departures and arrivals of messages are called events. Though not explicitly identified, events occur whenever a message is sent or received by an actor. Events, such as the arrival of a Payment at the Company, are important stimuli to the system (as are the sending of a Shipment, receipt of an Invoice, etc.).
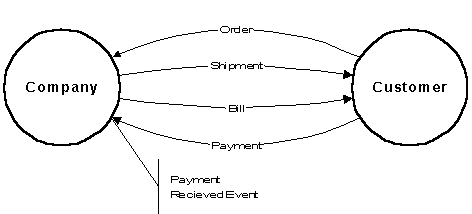
Figure 3: Implied Event
The messages depicted on the diagram are also typically about something of value: products, services, land, money, etc. We term these things of value commodities, and again they are implied on the diagram and not explicitly shown. [We originally called them objects, but changed the name when, well, you can guess…].
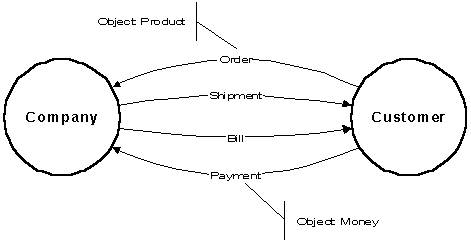
Figure 4: Implied Commodities
Lastly, the channel of communication between the Company and the Customer represents one type of relationship that can exist in the system context (there are other types of relationships as well, such as product hierarchies and other groupings, assignments of a discount for a given product to a particular customer, etc.).
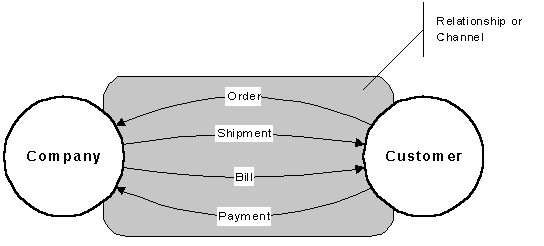
Figure 5: One Relationship
It turns out that actors, commodities, relationships, messages and events represent the five fundamental classes of logical files developed in our method. Why they are important will be addressed shortly. Before that, however, one other bit of terminology and philosophy should be noted, particularly to those familiar with relational design methods. In the Warnier/Orr method a logical data base design consists of a set of flat files known as Logical Basis Files (LBF's). While LBF's look a lot like a classic relational data model, they are not. One important distinction is that LBF's are related to one another via a set of logical linkages called logical record IDs. While this is similar to the primary key/foreign key seen in a relational data base design, a set of LBF's differs principally in the type of data that is used to relate logical files to one another. The Warnier/Orr method makes a distinction between two different kinds of data elements: Application data are the facts and figures that must be stored to satisfy the output requirements of the system-basically, all the data that is visible to and meaningful to the end-user community. Application data are elements such as the Customer Name, Employee SSN, and Product Description. Structural data are the relationships or linkages that must be preserved between LBF's. These relationships retain the knowledge that an Invoice belongs to a particular Customer, or that an Employee works in a certain Division. The principal difference between a conventional relational data base design and a Warnier/Orr logical data base design lies in the way structural data is preserved: In a Warnier/Orr design application data is never used as structural data; in a relational design application data is always used as structural data. Keeping the structural data logically apart from the application data allows a Warnier/Orr logical data base design to retain maximum flexibility without sacrificing the end-user's ability to manipulate their application data in certain important ways.
Another valuable attribute of the Warnier/Orr method lies in its data classification schema. Since every piece of application data in a system should represent a fact about something of interest in the real world, it is incumbent upon a methodology to categorize these "things of interest." As mentioned earlier, the Warnier/Orr method classifies them into five distinct categories: actors, commodities, messages, events, and relationships. A logical data base will contain Logical Basis Files from each of the five classes. LBF's of a given class will behave in a manner similar to other files of the same class, and will have similar rules for determining proper formation, updating, and use. This feature makes the analysis of the data far easier than traditional methods, and the behavior of the data base far more predictable. Many physical characteristics of files, such as their organization and performance requirements, also may be deduced from the file's class. Understanding each of these five classes of data is an essential key to building correct logical data base designs. They are defined as follows:
Actors are those people, organizations, or automated systems acting in place of people who can initiate or receive communication. Therefore actor-class logical basis files contain data about people, organizations, and other systems. One logical actor record will typically contain information about the actor's name, location, and other information of interest to the system (such as credit rating, phone number, and so on).
Commodities are those things of value about which actors communicate. Therefore, commodity-class logical basis files contain data about such things as products, services, property, and information. One logical commodity record will typically contain information about the commodity's name and other information of interest to the system (such as price, regulated status, unit of measure, and so on). Both actor and commodity files generally contain date/time stamps indicating when the actor or commodity was created in the system and when it was last updated in the system.
Actor and commodity files are often grouped together as a single class, since they share important formation and updating rules. One important characteristic of both actor and commodity files is that they represent things in the real world for which information can be "created" in a system well before it is "active," and can also have information "deleted" from the system well before it is actually "purged." Thus, actor and commodity records tend to be very long-lived in a system, and the information kept about actors and commodities must be modified as the people and products they represent change over time. Not only do the values of specific attributes change over time (such as Customer Address), but the number of attributes and their meaning may change as requirements change. In other words, we not only must be able to change the value of Employee Name when employees change their names, we must also be able to add Ethnic Classification or delete Sex Code from the record as governmental reporting and/or privacy requirements change.
Another interesting characteristic of both actor and commodity files is that their records do not contain logical references to other logical files (the moral equivalent of foreign keys): a Customer record would not contain information about which Products the customer purchases. Instead, this structural information is kept by message or relationship class records that will be discussed presently. Keeping structural information out of actor and commodity-class records is the consequence of an observation fundamental to the Warnier/Orr approach: the belief that there are no inherent relationships between actors and commodities other than ones that reflect their behavior in the system. This characteristic of actors and commodities is also consistent with the observation that actors and commodities rarely have one-to-one relationships with other logical files; therefore structural information cannot be stored with the actor or commodity but instead must be stored with records that relate them to one another.
Messages are those "packets" of information or instances of commodities that are exchanged between actors. Thus, message-class logical records contain data about exchanges. One logical message record will often contain two types of data: the application data concerning an exchange (such as its date, number, quantity, and so on), and the structural data about the exchange (what actors, commodities, or other messages did it involve). Unlike actor and commodity files, message files must necessarily reference data in other logical files. Message records also tend to have different creation and deletion requirements from actor and commodity records. Message records are rarely created before they are activated (they are not created by the system before they become active) and are rarely deactivated and then later purged (the delete and purge occur at the same time: when there are no longer any reporting requirements for the message). In addition to being more short-lived in the system, message records also tend not to be updated as actor and commodity records are. Once a message is entered correctly into the system, rarely does the need arise to update its application data. Further when reporting requirements precipitate changes to the message record, rarely is the new information gathered retroactively for old messages. Instead the new data is gathered for only messages that occur after the changes to the requirements have been implemented.
Relationships are those associations between actors, commodities, and messages that are preserved to remember formation rules or business practices. Thus relationship-class logical records contain information about the system's structure. A logical relationship record will typically consist of only structural data and very little if any application data. A relationship record may store information about which actor class is related to what other actor class, which actor can exchange a commodity, or which messages are sent to which actor. Generally, relationships are best expressed as binary associations, but can on occasion involve associations between more than two logical files at a time. For instance, structural data preserving information such as an employee "working for" a department, or an instructor "teaching" a course would be binary, while the relationship between an instructor, a student, and a single offering of a course, might be a valid 3-way relationship. Binary relationships are generally free of update anomalies related to the inadvertent deletion of information in a system. [Consider, for example, a 3-way relationship between Company, Customer, and Sales Agent (where the Company/Agent relationship is one-to-many, the Agent/Customer relationship is many-to-many). A relationship file may be built containing every valid Company/Agent/Customer combination--in effect, storing information about which Agents work for which Companies, and which Customers they have. If a Customer only has one Agent for a given Company, deleting the Agent's relationship with the Company when the Agent leaves would inadvertently delete information relating the Company with that Customer.] Relationship files occupy a middle ground between actor/commodity files (which are relatively long-lived and contain no structural information) and message files (which are relatively short-lived but can contain structural information). Relationship files can share some of the behavior characteristics of actor and commodity files (in their creation, updating, and deletion rules) as well as some of the formation rules for message files (in that they can contain structural references to other logical files). Like actor and commodity files, relationship files can contain date/time stamps for activation and deactivation, as well as other application data (for instance, a "discount" relationship may involve an association between an actor and a commodity, may be created before it is activated, may be deactivated before it is purged, and may contain application data such as discount percentage). Therefore relationship records tend to be more long-lived than message records, but more short-lived than actor and commodity records. In general, relationship files that associate actors to actors, actors to commodities, or commodities to commodities behave as actor and commodity files; relationship files that associate messages to actors, messages to commodities, or messages to messages behave as message files.
Events are those "happenings" in the real world that require the information system to produce outputs or to consume inputs. Thus, event-class logical files contain data associated with events of interest to the system. In general the application data associated with one logical event record is time-related: it indicates when the event of interest occurred (usually a date/time stamp). An event record can also contain data for selecting other data from the logical data base. For instance, an event record for a "request for product price" would include not only the date/time stamp of the request, but also a search argument for a particular product. Event records tend to be the most short-lived records in the data base, since it is necessary to keep them for only as long as it takes to generate a response to the event. Event files also generally contain at most one record at a time (it is rare to have to "remember" a list of events upon which action must be taken, except under a physical implementation where the events can occur more rapidly than the system can respond to them).
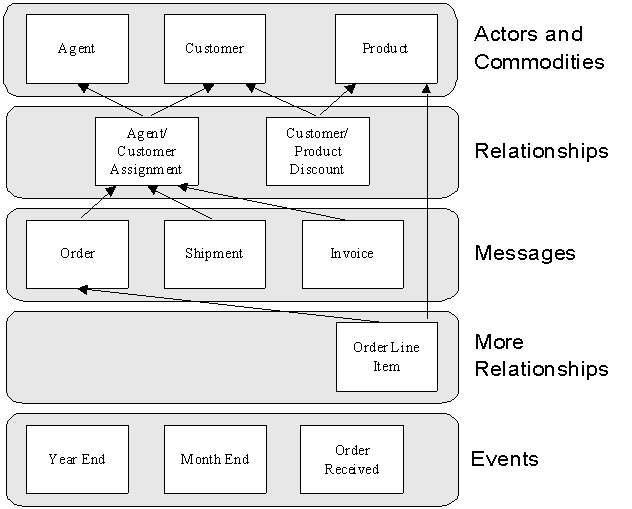
Figure 6: Logical Basis Files
Developing
Logical Basis Files
In the Warnier/Orr approach we develop the Logical Base Files in
two stages. In the first step the logical base data elements (the
application data) are "sifted" into logical base files.
In the second step structural data is added to the logical base
sets so that necessary data relationships are preserved. In this
section we illustrate the analysis done on the data and the data
structure.
The assignment of the base data elements to the correct logical base file is the first critical step. This assignment is done by first classifying the element by the type of logical file to which it belongs (event, actor, commodity, message, or relationship). Then, the specific logical base file is named. This process can be summarized as the following two questions: For base data element "X": 1) Does a single value of "X" represent data about an event, an actor, a commodity, a message, or a relationship? 2) Specifically, what is the name of the [choose one: (event) (actor) (commodity) (message) (relationship)] that "X" represents data about? For example: Customer Name is an attribute of an actor called Customer; Invoice Number is an attribute of a message called Invoice; Customer Product Discount is an attribute of a relationship between a Customer and a Product, and so on.
There are often occasions when the first question cannot be immediately answered. In other words, it is not apparent from the name of the base data element what kind of base file the element represents. When this occurs, additional questions may be asked to help ascertain its pedigree. If the data element's classification type is unknown or indeterminate, one may ask instead: How long would the value of the data element have to persist in the system? Data elements whose values need to be kept only long enough to produce an output or to collect on an input most likely represents event data; those whose values are needed from a few minutes to a few weeks most likely represent message data; those whose values must be kept for a few months to many years most likely represent actor or commodity data. As an alternate strategy we may try to eliminate some classifications from consideration, and thus narrow the possibilities down.
There are also many occasions where there is no immediately obvious name for a logical base file (particularly for message and relationship files). When no good name can be found, it is best to generate a temporary name and continue on until a better name is suggested. For relationship files, the temporary name can be generated from the name of the files related concatenated with the term "assignment," as in "Company/Vendor Assignment" or "Division/Employee Assignment." For message files, the temporary name can be generated in a similar manner, except using the term "exchange," as in "Company/Employee Exchange."
Once the base data elements have been "sifted" into their respective logical basis file "bins," we begin to assign structural data to the system. The first step in the assignment of structural data is to give each logical base file a unique logical record identifier. This logical identifier is the moral equivalent of a primary key: it is assumed that each record in a logical basis file is uniquely associated with its logical record identifier. Thus, each record of a Customer basis file is assigned a Customer ID; each record of an Invoice basis file is assigned an Invoice ID, and so on. Keep in mind that although this ID is the logical equivalent of a primary key, it is not necessarily going to be implemented in the physical data base as a primary key: that is just one possible physical implementation.
As a second step, the data structure for each output of the system is examined. Each output data structure will tell us how the logical base files must be related together to be able to produce this particular data structure. The key to this analysis lies in the definition of the message and the relationship files which must be extracted from the data base to "drive" the production of the output. These "driver" files are those that represent the data found at the lowest level (or levels) of the output data structure. To put it in different terms, the "driver" file is the message file from which records are selected to form the basis for the data on an output.
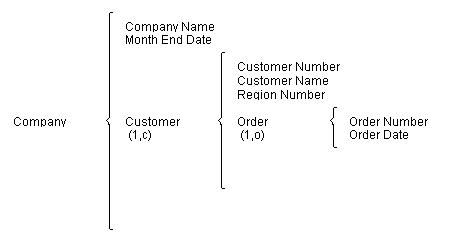
Figure 7: Output Data Structure
Examination of the above data structure (which indicates that the output consists of Orders grouped by Customer for the Company) should lead the developer to conclude that the Order message file is the driver file for this output; order records must be extracted from the data base according to some reporting criteria (such as month end), and therefore each order must carry structural information necessary to build the view of the data base represented by the data structure. Thus the order records will have the following identifiers added: 1: Customer ID (so that orders may be hierarchically grouped by customer and so that the Customer Number and Customer Name can be obtained from the data base), 2: Region ID (so that Region Number can be associated with an order, as indicated on the diagram), and 3: Company ID (so that orders can be grouped by company, as indicated on the diagram, and so that Company Name can be obtained from the data base). The Logical Base Files (before any optimization of structural data) is as follows:

Figure 8: Unoptimized LBF's
While beyond the scope of this paper, additional analysis of other outputs in this system would yield several obvious pair-wise relationships, such as the Company/Customer (the relationship that a Customer can transact business with the Company) and Region/Customer (the assignment of Customers to particular Regions). Thus, the optimized version of the logical basis files would likely appear more like the following:
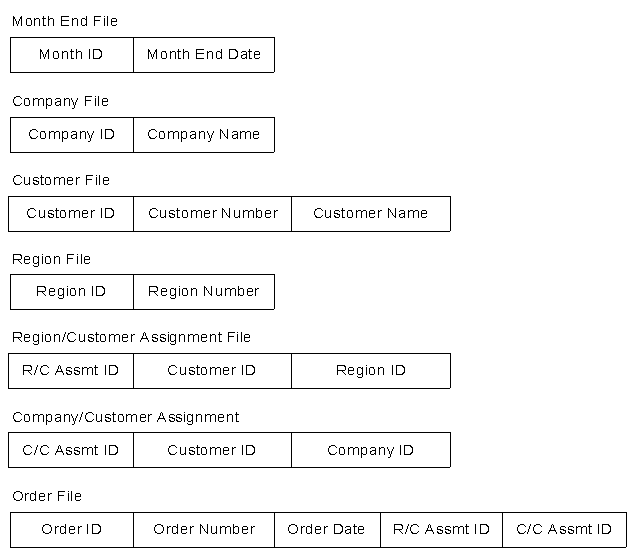
Figure 9: Optimized LBF's
Over-Normalization
One of the classic problems facing data base developers is a
question of over-normalization: how much normalization is
appropriate for logical design, and when does it become too much.
The best advice that can be offered is to normalize only to the
extent that the output requirements and the updating requirements
of the system demand it (and even then, be careful).
Probably the simplest example of over-normalization typically occurs when examining dates and addresses. Both date and address are compound physical fields (date contains year, month, day, and perhaps hour, minute, and second as well; address contains street address, city, state, and zip code). It is rarely useful on address, for instance, to break apart city, state, and zip code for the purposes of logical design, even though keeping them together may technically generate updating anomalies (when changing a city name or zip code, multiple records must be consistently updated, and if only one address contains a particular city and state, deleting that record destroys information in the system relating city and state). Unless the usage of data dictates a reasonable expectation that zip code, for instance, represents an interesting and important grouping of actors, it should not be normalized to its own file. A postal system relating mail carrier to zip code, or an emergency response system relating zip code to fire station, for instance, would be instances of systems where there is sufficient justification for creating a zip code area file, with various relationships stored in the system to that file.
Another classic kind of over-normalization occurs when dealing with attribute values. Normally, consideration for an element being in one logical file as opposed to another is based on whether two records in the same file can contain the same value for that attribute. For instance, if two invoice records can have the same value for customer name, then customer name is not an appropriate element to be stored on the invoice record, but should be normalized out into a customer file. This is because a relationship is implied: if two invoices have the same customer name, they are for the same customer. However, the same is not true within the customer file itself. Asking the question "can two customers have the same name?" may very well yield the answer "yes." This is not justification for normalizing name out to another file, since there is no relationship implied (if one customer with the name "Acme" changes their name, does that mean that other customers with the name "Acme" also should change--clearly not).
Perhaps the most difficult over-normalization issues revolve around alternative data, and subsets of base files. Consider a system where customers are stored--some are active and some are inactive. A single attribute "customer status" stored on the customer file is sufficient for this system. However, consider a medical system where the sex of an individual determines what information must be kept. In this case, a sex code on the patient record is not sufficient to store information necessary, since depending on the value in the code, different attributes must be kept for the patient. In this type of system, sub-sets of the patient file will be appropriate (a male patient file keeps male medical history while a female patient file keeps female medical history). These sub-sets of an actor file (patient) are a kind of relationship file, relating information about a patient to a particular class of patients.
Relational
Data Base Concepts
Relational data base concepts, while similar to those found in
the Warnier/Orr Logical Data Design (LDD) approach, are different
in both form and substance. The principal difference between the
Logical Basis Files (LBF) developed in LDD and classic 5NF
relational files is that the LBF's represent the logical data
needs of a system--relational files are meant to represent a
physical means of storing the system's data. Of course, LBF's can
be implemented directly as pure relational files. This is done by
making each LBF into one relational file and by making the
logical record ID's into key fields. LBF's can also be
implemented in non-relational environments (hierarchical or
network data base management systems) as well, by using the
relationships indicated by the logical record ID's as DBMS
maintained relationships not directly available to the end-users
of the system.
Another difference between LBF's and data normalization techniques is one of basic intent. LDD is a set of steps intended to lead the data base developer to discover a correct set of logical files and their logical relationships, while data normalization is a set of quality evaluation rules. Normalization does not tell the developer which logical file a particular data element belongs to, but instead provides a set of guidelines to help determine when an element has been placed in the wrong file.
LDD and traditional relational methods do share some common goals. The underlying goal of data normalization is to eliminate updating anomalies from a data base. This is done by analyzing individual files to look for known kinds of updating anomalies (updating anomalies being inadvertent errors introduced into the data base by adding or subtracting records from the system). A secondary goal of data normalization is to create a data base wherein each data element is stored in only one place (although this too is really related to an updating anomaly: when data is stored in more than one place there is the danger of changing it in one place and failing to change it in another, resulting in inconsistent data). These goals are laudable and quite compatible with the goals of the Warnier/Orr approach. While the principal goal of LDD is to develop a logical data base which models the "real world" as closely as possible, it achieves as a by-product the same goals as traditional normalization.
Normal
Forms
Traditional normalization methods define several different
"normal" forms of data. If you consider all
possible file implementations, only a subset of those are said to
be in "1st normal form;" of the files in 1st normal
form (1NF), only a subset of those is in "2nd normal
form;" of the files in 2NF, only a subset of those are in
3NF, and so on. Pictorially, this can be represented as
follows.

First Normal Form - 1NF
A single tuple (row) in the file may contain at most one occurrence of an attribute (column). In other words, if the file contains only records of fixed length, and each field is present only once on each record, then the file is in 1NF. This is also known as a "flat" file or a "relational" file.
Note that in order to implement a set of files in a relational data base, 1NF is the only requirement; other higher normal forms may be implemented, but files in 1NF but not in 2NF are permissible (and sometimes even desirable for performance reasons).
Second Normal Form - 2NF
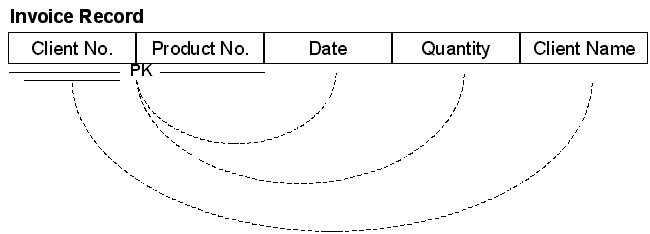
A functional dependency is one in which data on the record is related to only a portion of the primary key, and not the entire primary key. In the example above, for instance, the Date and the Quantity will vary with each Invoice (identified by the Client Number and Product Number). The Client Name, however, does not vary with each Invoice, but rather will vary with each Client: therefore the record is said to contain a functional dependency. Note that functional dependencies cannot exist unless the Primary Key is compound (made up of two or more data elements).
A record that is in 1NF and that has no functional dependencies is said to be in 2NF.
Third Normal Form - 3NF
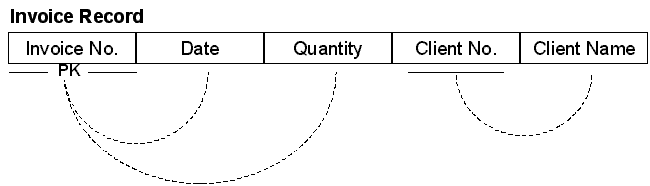
A transitive dependency is one in which data is related to some other piece of data on the record other than the primary key. In the example above, Date, Quantity and Client Number are all related to the Invoice, but Client Name is related to the Client Number. Therefore the record is in violation of 3NF. Note that the problem is basically the same as with a 2NF violation: incorrect data is present on the record (the Client Name).
A file that is in 2NF and that has no transitive dependencies is said to be in 3NF.
[By the way, "3NF" as used by most developers today is also known as BCNF: Boyce-Codd Normal Form. Turns out there was a bug in the original definition of 3NF, so Boyce and Codd (hence the names) redefined it to remove the bug. The redefined 3NF (a.k.a. BCNF) is what most developers mean when they refer to 3NF.]
Note that most database designers are quite happy to stop the normalization process when they reach 3NF. Examples in the real world that violate the two higher normal forms are rarely seen, and in fact are usually due to failures to correctly implement a 1NF version of real-world relationships of data. That being said...
Fourth Normal Form - 4NF

A multivalued dependency is one where there are dependencies within the primary key. Notice that in the above case, if only one instructor teaches a class, then the deletion of that instructor (and all the rows containing reference to that instructor) would delete the class that the one instructor taught, as well any textbooks used by only that class. This is known as an update anomaly: where the deletion of one fact from the database inadvertently deletes unrelated facts. Also notice that in the real world, no competent database developer would create such a table. The relationships stated in the assumption would be implemented as two tables: one that assigns instructors to the classes they teach, and one that assigns textbooks to the classes in which they are used.
A file that is in 3NF and that has no multivalued dependencies is said to be in 4NF.
Fifth Normal Form - 5NF

A join dependency is the general case where there are intra-key dependencies. It is known as a join dependency because it is the last kind of dependency that can be solved by splitting the record apart [technically known as a project (as in "project a movie onto a screen," and not as in "manage a project"), which is the reverse of a join in relational file operations]. In fact, the 4NF example above is also a type of join dependency: the only difference between 4NF and 5NF is that files in violation of 4NF must be split into an even number of files, while files in violation of 5NF must be split into an odd number of files.
Since you can't solve updating anomalies by further splitting records apart into separate files, 5NF is the last of the "normal" forms. Note that the upshot of this comment is that it is entirely possible to design a series of files that is in full fifth-normal form and yet still contains updating anomalies.
Logical
Basis Files vs. Normal Forms
In a relational file, a primary key is the data element (or
concatenation of several data elements) that contains a value
that uniquely identifies one and only one record. The primary key
can be installed on other records of other files (it is called a
foreign key when present on other records) as a means of relating
one set of data to another. When implementing LBF's as relational
files, the simplest physical implementation is to mirror the
logical file structure by creating the logical identifier for
each LBF as its primary key. Logical identifiers implemented as
linkages on message and relationship files then become foreign
keys. The traditional 1st through 5th normal forms may be
compared with such a literal implementation of Logical Base
Files.
1st Normal Form - "No Repeating Attributes" Guaranteed by the analysis of the logical base data. No data element is allowed to be assigned to a logical file if that element occurs more than once for each record in the file.
2nd Normal Form - "No Functional Dependencies" Guaranteed. Since files which have this type of dependency have compound primary keys, all Logical Base files satisfy this requirement by definition: no compound primary keys are allowed.
3rd Normal Form - "No Transitive Dependencies" Guaranteed for event, actor, and commodity files. Possible similar updating anomalies will exist if actor or commodity data is incorrectly kept with a message or relationship. The analysis of the data minimizes this likelihood.
4th Normal Form - "No Multivalued Dependencies" and 5th Normal Form - "No Join Dependencies" Since both 4th and 5th normal form violations deal with "inter-primary key" relationships, these are guaranteed normal forms for Logical Base Files. Similar updating anomalies may exist if binary relationships present in message files are not extracted to become relationship files, but the analysis method minimizes this risk.
Home | What's New | What's Old | Articles | Associates | Interesting Links | Cool Stuff |
This web site and all
material contained herein is Copyright ©2002-2009 Dave
Higgins. All Rights Reserved. For additional information,
please contact me at: |